Pyannote AI révolutionne la reconnaissance vocale
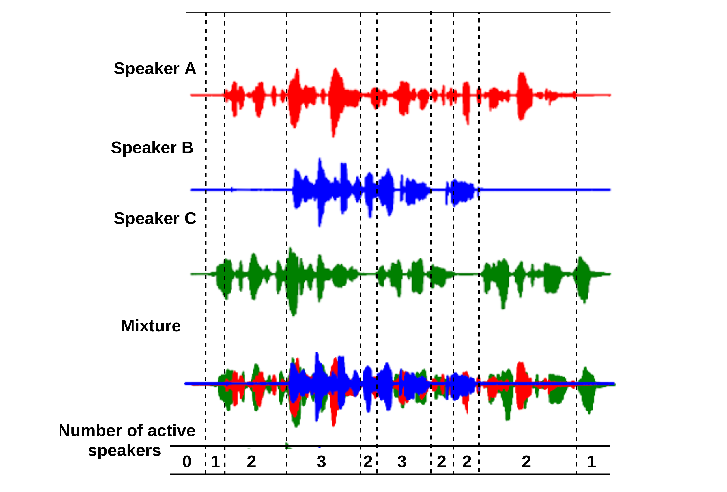
Créée en mars 2024, la start-up PyannoteAI se fonde sur l’intelligence artificielle pour procéder à la diarisation, autrement dit l’identification de « qui parle quand » dans une conversation. Une technologie qui pourrait très vite élargir les domaines d’application de cette solution unique, développée au sein de l’université de Toulouse et du CNRS.
Avant de licencier la technologie avec Toulouse Tech Transfer (TTT) en avril 2024, il a fallu dix ans de recherche et développement à Hervé Bredin, de l’Institut de recherche en informatique de Toulouse (IRIT) (Université de Toulouse/CNRS) pour réussir à partitionner un flux audio en segments temporels homogènes en fonction de l’identité du locuteur.
Pour réussir le développement de Pyannote, dotée d’une technologie de pointe (vitesse de traitement de l’information et précision dans l’identification du locuteur), Hervé Bredin s’est appuyé sur ses travaux, mais aussi sur les technologies de machine learning et sur la puissance de calcul du supercalculateur du CNRS (125PFlop/s). Résultat, la start-up a réussi à lever les différents verrous technologiques : le dénombrement des personnes dans une conversation, la détermination de l’instant où chaque personne prend la parole et l’extraction des paroles individuelles lors d’une « zone de parole superposée ».
Il manque un maillon essentiel pour rendre intelligible la transcription d’une conversation, c’est la capacité à identifier “qui parle quand”, et c’est là que Pyannote entre en jeu.
Vincent Molina, PyannoteAI
Deux versions proposées
Des performances qui ont permis à la start-up de résister à l’assaut des technologies plus grand public. « En 2022, OpenAI a lancé un outil de transcription démocratisant les techniques de reconnaissance automatique de la parole et ouvrant la voie à des milliers d’applications grâce aux IA génératives. Pour autant, il manque un maillon essentiel pour rendre intelligible la transcription d’une conversation, c’est la capacité à identifier “qui parle quand”, et c’est là que Pyannote entre en jeu », précise Vincent Molina, cofondateur et CEO de PyannoteAI.
Pour l’instant, l’entreprise a développé deux formules. « Nous sommes sur un modèle économique freemium avec la version historique en open source et une version premium payante proposée en BtoB. Nous déploierons une proposition sur étagère (diarisation d’une bande audio confiée par le client, par exemple) et une proposition plus intégrée au sein des systèmes de nos clients. Ces derniers seront, notamment, des acteurs du marché de la transcription, de l’audiovisuel ou, encore, du secteur de la santé. Pour respecter des niveaux de confidentialité particuliers, rencontrés, entre autres, dans le secteur médical ou dans celui de la finance, nous présenterons une version on-premise que le client installera en local ; ses données ne transiteront pas par un serveur », poursuit Vincent Molina.
Aujourd’hui, la version en open source écrite en Python, version historique simplifiée, permet déjà à des milliers de sociétés (fournisseurs de services de transcription, médias, sociétés commerciales), des académiques et des développeurs indépendants d’utiliser la technologie pour créer des produits. Disponible sur GitHub (github.com/pyannote/pyannote-audio), la version 3.1 procède en trois étapes : la segmentation en tours de parole, l’extraction de représentation neuronale de chacun d’eaux et leur regroupement par locuteur. Pyannote open source a notamment été primée lors de nombreux benchmark : premier à Ego4D 2022, premier à Albayzin 2022, troisième à VoxSRC 2024 et premier à Displace 2024.
Transcription de la conversation à venir
« Pour l’instant, nous sommes dans une bonne dynamique de lancement. La technologie est prête et la société est créée. Nous avons déjà engagé des discussions commerciales avec plusieurs centaines de clients potentiels utilisant, notamment, la version en open source. Nous établissions notre feuille de route de développement pour les prochains mois et les prochaines années », ajoute Vincent Molina.
Et les perspectives de développement de Pyannote sont immenses. « L’IA va s’attacher à comparer et à identifier le timbre, donc il n’y a pas de limites en termes de langues », se réjouit Vincent Molina. PyannoteAI ne souhaite d’ailleurs pas proposer seulement des algorithmes de diarisation et entend aller plus loin dans la chaîne de valeur de la reconnaissance vocale. Dès la rentrée de septembre 2024, la start-up compte coupler, en aval de Pyannote, une technologie de transcription de la conversation (conversion de la parole enregistrée en texte). Autres perspectives de développement à moyen terme pour la jeune pousse toulousaine : la proposition de la technologie de diarisation en temps réel (streaming) et la création de modèles sur mesure pour ses clients (analyse, extraction de données, etc.).
Au salon Vivatech de Paris, qui se tiendra du 22 et 25 mai, Pyannote AI prendra la parole sur le stand du CNRS et participera à une table ronde sur la thématique « l’écosystème dans l’accompagnement de l’émergence d’innovation deeptech ».
Le réseau SATT
Le réseau SATT fédère, en France, treize Sociétés d’accélération du transfert de technologies (SATT). Engagées dans le dynamisme économique grâce aux innovations scientifiques, les SATT apportent aux entreprises des solutions technologiques dérisquées, à fort potentiel, pour gagner en compétitivité. Avec plus de 700 start-up créées, les SATT sont les premiers acteurs de proximité du Plan Deeptech de l’État, opéré par Bpifrance. Elles sont connectées au quotidien à plus de 150 000 chercheurs et offrent un accès privilégié aux innovations des laboratoires publics. Fortes de leur réseau national, elles sont les partenaires stratégiques des entreprises en quête de croissance par l’innovation. Plus d’informations sur le Réseau en cliquant ici.
Découvrez d'autres articles sur le même sujet





